In this article I’d like to summarise my knowledges and understanding of the new buzzword Reverse ETL.
No long introductions, let’s jump into the topic.
Let’s start with definitions, what is ETL and Reverse ETL?
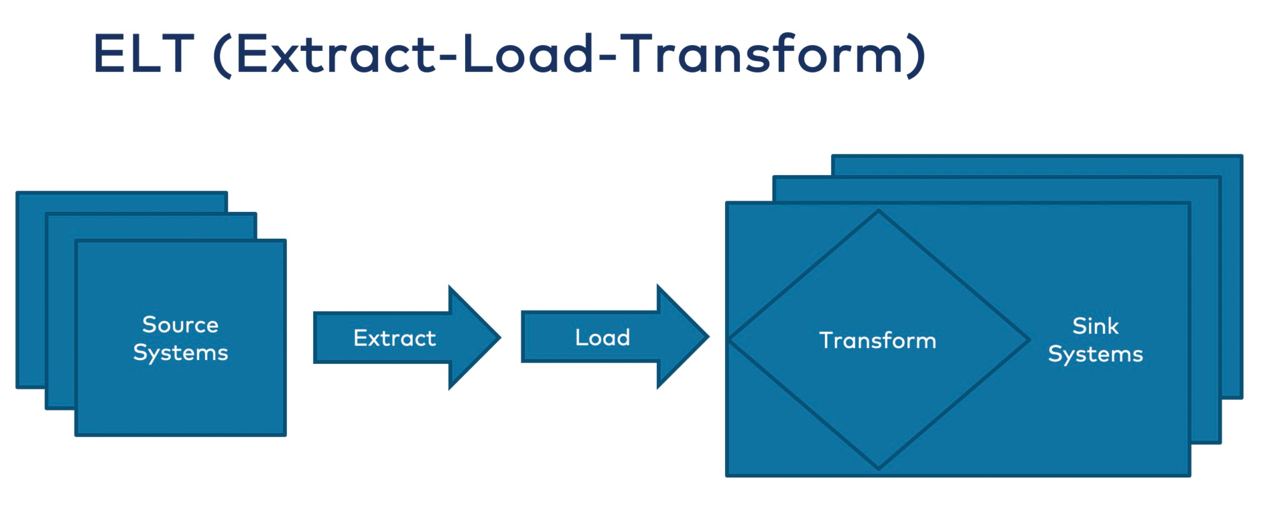
ETL (Extract-Transform-Load) - a common term for data integration, a process of bringing data from sources to your datawarehouse, or data lake.

Modern data storage and analytics vendors also recommend utilising ELT approach, when transformations and aggregations happen after the load into the datastore.
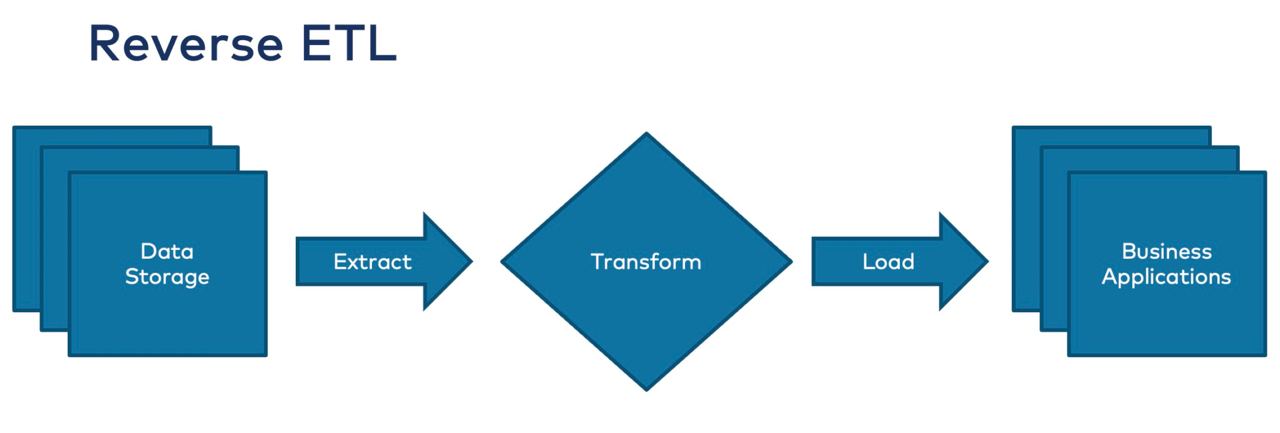
So what is reverse ETL? As you could guess out of the name - it turns the story the other way around, i.e. it’s the process of moving data from the central datastore to operational systems.
Just google for “Reverse ETL” to find different vendors pitching their solutions. Most of them would be relatively young, during my research I’ve found Hightouch, Census, Grouparoo, Rudderstack, Rivery.
Use-cases examples for reverse ETL:
- Identify customer at risk, to prevent customer churn before it happens
- Drive new sales by matching data from CRM and other sources
- Data replication to cloud apps for finding new insights and operational analytics
A regular task for any data engineer is writing a new ETL connector for a new source (or using special tools to ease the process). But having an ETL connector doesn’t mean that a reverse ETL connector is also available. In fact, the most common case would be the need to build a reserve ETL connector separately, and to take care about API endpoints, rate limits, etc.
Real-time scenario requirements:
In cases when real-time data analysis gives significant benefits (in my personal opinion it’s not always the case), it might be complicated to combine it with a reverse ETL - imagine you have hundreds of thousands events per minute, it’d be difficult to process all the events through a datawarehouse, designed primarly for batch and complex analytical queries. So in this case it probably makes sense to utilise a regular streaming solutions, like Kafka, optionally with KSQL, and stream necessary data into it, combining in together within the stream itself.
I personally find the concept of reverse ETL very inspiring, transforming a traditional DWH or data lake into a source of truth across all the systems and 3-rd party providers used inside the company.
Exciting times we’re living in!